In the previous part, I showed the main loop to grab the "interesting bits" from the HTML of my Sporting News' BLOG. Let me dig into this a little more. On the BLOG, a typical entry looks like this:
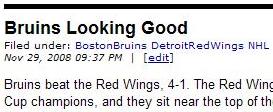
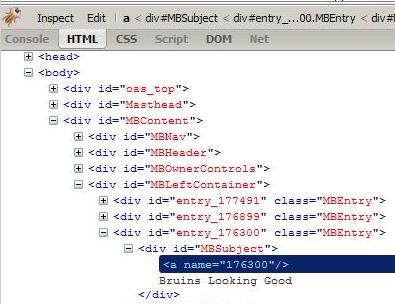
Using Firebug ("View Source" is so 1990s), I can see the id and class attributes of the div elements. The div that identifies each BLOG entry is class="MBEntry".
- while (my $div_tag = $stream->get_tag("div")) {
- if ($div_tag->[1]{class} && $div_tag->[1]{class} eq "MBEntry") {
- my $id = $div_tag->[1]{id};
- $subject{$id} = get_subject($stream);
- $pubDate{$id} = get_pubdate($stream);
- $text{$id} = get_entry($stream);
- }
- }
In line 1, the HTML::TokeParser's get_tag() method returns an HTML "tag", complete with attributes. This return value is stored in a Perl array reference, which contains one of these arrays, depending on whether we're looking for a start or an end tag:
["/$tag", $text] // End tag
Since we're looking for a start tag, this means that $div_tag->[1] returns the $attr element. The $attr element is a Perl hash reference, which contains the attributes of the tag, each attribute value ("MBEntry") using its name ("class") as the key. This means that $div_tag->[1]{class} returns "MBEntry". Every time this "if" statement evaluates to true, I have found a BLOG entry.
Once I have a BLOG entry, I use separate functions to walk down the HTML a little further to get more specific information. To get the subject, for example, you'll observe from the Firebug screen shot above that there's an anchor element before the actual text. The function get_subject (excerpted below) consumes this anchor tag first (line 5), before getting the text containing the BLOG's subject (line 6).
my $stream = shift;
while (my $div_tag = $stream->get_tag("div")) {
if ($div_tag->[1]{id} && $div_tag->[1]{id} eq "MBSubject") {
$stream->get_tag("a");
$stream->get_token();
$subject = $stream->get_trimmed_text();
return($subject);
}
}
return ($subject);
}
The other functions (get_entry() and get_pubdate()) each examine the HTML in a certain way to get at the pertinent text. You can look at the source code to see what I've done. Some of it is tricky, but it's not too hard.
As mentioned in the previous post, the output of all this is a list of each BLOG post with their respective titles, subjects and publication dates. At this point, the only thing left to do is walk through this list and generate the RSS XML. That's the subject of the next post.
The full source code is at feedsn.pl.